查看往期文章請(qǐng)點(diǎn)擊右上角,關(guān)注查看歷史新聞
所有文章都經(jīng)過分類和組織,使您更容易查找和閱讀。 請(qǐng)?jiān)陧撁娌藛沃姓业剿?span style="display:none">yUd物理好資源網(wǎng)(原物理ok網(wǎng))
手寫數(shù)字的機(jī)器識(shí)別問題早已得到解決,MNIST數(shù)據(jù)集中機(jī)器識(shí)別的準(zhǔn)確率已經(jīng)超過99%。 事實(shí)上,這些問題還沒有通過硬編碼一一解決,我們不得不承認(rèn)機(jī)器確實(shí)學(xué)到了一些東西。 但我們好奇的是機(jī)器學(xué)到了什么? 它是如何學(xué)習(xí)的?
問題設(shè)置
我們現(xiàn)在有 60,000 張手寫數(shù)字圖片,已在 MNIST 數(shù)據(jù)集中進(jìn)行了標(biāo)記。 每張圖片都可以看成一個(gè)(28,28)的二維域,如下圖所示。 我們需要從這些訓(xùn)練數(shù)據(jù)中預(yù)測(cè)未標(biāo)記的數(shù)據(jù)。
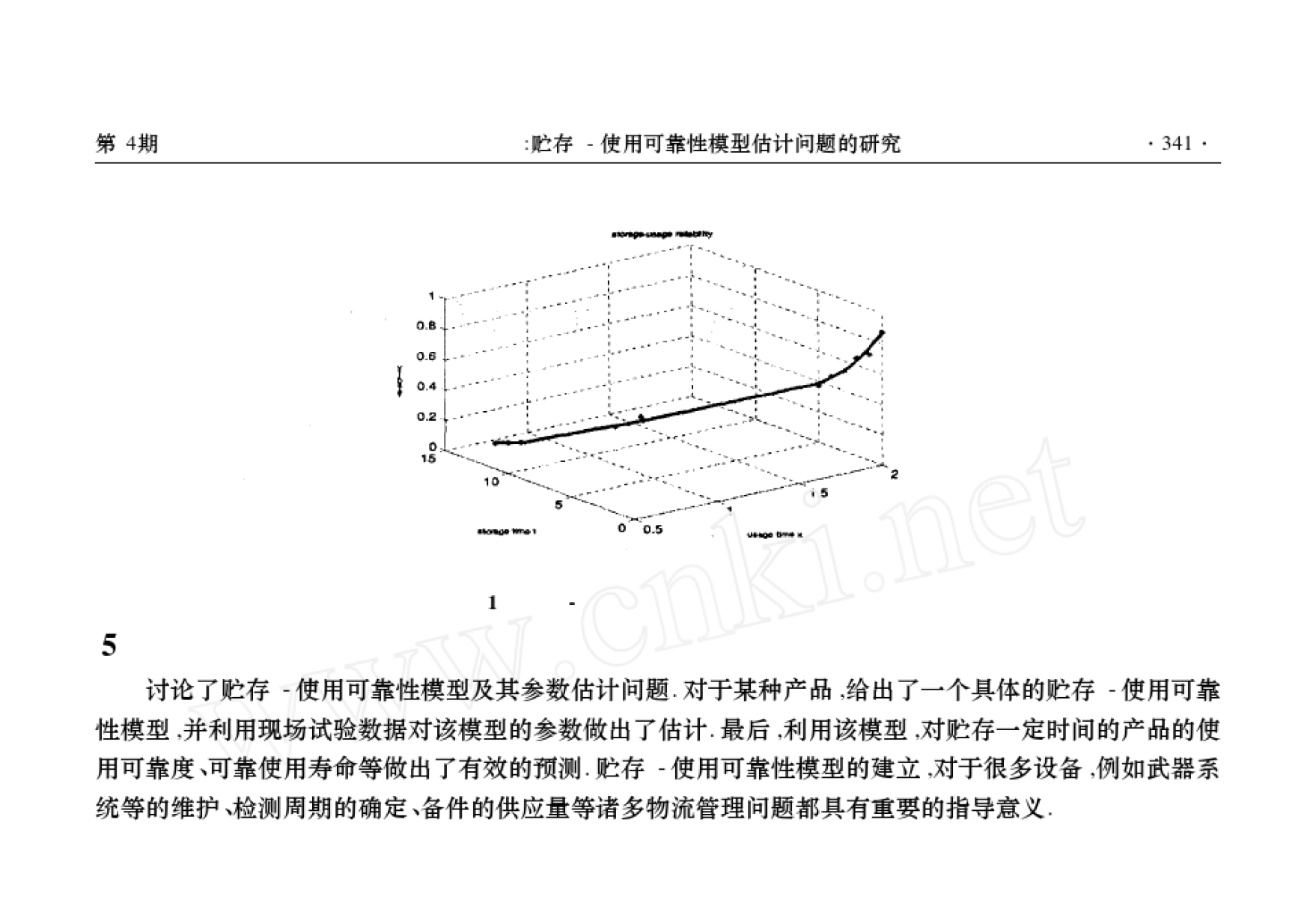
思路
我們得到一張未知的圖片,我們將它與訓(xùn)練集中的所有圖片進(jìn)行比較,我們找到訓(xùn)練集中與它最相似的圖片,如果這張圖片的標(biāo)簽是k,我們可以說我預(yù)測(cè)了未知的圖片的手寫數(shù)字也是k。 這種手寫數(shù)字識(shí)別方法確實(shí)有效。 KNN算法稍微提升了這種方法,取得了90%以上的好結(jié)果。 我們能夠使用這些方法非常快速地檢測(cè)到問題。
首先,我學(xué)到了什么? KNN算法實(shí)際上并沒有學(xué)習(xí)任何東西,它只是存儲(chǔ)了已知的數(shù)據(jù),沒有真正的“訓(xùn)練”過程,所以我們每次預(yù)測(cè)都需要大量的估計(jì),我們拿出一個(gè)訓(xùn)練數(shù)據(jù)集來與訓(xùn)練數(shù)據(jù)集進(jìn)行比較需要預(yù)測(cè)的事情需要大量資源。
另外,如果新的機(jī)器學(xué)習(xí)問題太復(fù)雜,例如識(shí)別人臉、對(duì)更復(fù)雜的圖像進(jìn)行分類,而我沒有足夠大的訓(xùn)練集怎么辦? 雖然我對(duì)每個(gè)復(fù)雜問題都有足夠的訓(xùn)練集,但當(dāng)我預(yù)測(cè)時(shí),它會(huì)帶來更多耗時(shí)的問題來估計(jì)。
理想的訓(xùn)練情境是怎樣的? 我的訓(xùn)練過程可能需要一些時(shí)間,一旦我完成訓(xùn)練,就需要非常快地做出預(yù)測(cè)。 例如,在新聞分類問題中,每天都會(huì)形成大量的數(shù)據(jù),每天晚上也需要對(duì)大量的新聞進(jìn)行分類,所以我們必須將預(yù)測(cè)時(shí)間限制在可控范圍內(nèi)。 另一個(gè)例子是量化策略中的預(yù)測(cè)。 如果需要一天的時(shí)間來預(yù)測(cè)未來三天的市場(chǎng),這些模型就不可靠。 高頻交易對(duì)時(shí)間的要求越來越嚴(yán)格。 如果下一步棋的預(yù)測(cè)過程需要30分鐘,那是絕對(duì)不可能打敗李世石的。
其實(shí)機(jī)器學(xué)習(xí)的過程應(yīng)該大致分為三個(gè)步驟:
1. 做出基本假設(shè)(什么模型可能是正確的?),確定模型的空間:線性模型? 非線性模型? 簡(jiǎn)單的模型? 復(fù)雜模型?
2.什么是“最好”的定義模型?:損失函數(shù)Loss
3.如何找到最好的? :梯度增長(zhǎng)法
1. 什么模型可能是正確的?
這是一個(gè)可能有效的模型:
這也是一個(gè)潛在有效的模型:=*input
第一個(gè)是微軟的深度神經(jīng)網(wǎng)絡(luò)模型。 模型非常復(fù)雜,參數(shù)很多,能夠?qū)W習(xí)的問題也比較復(fù)雜,學(xué)習(xí)過程比較慢,需要大量的數(shù)據(jù)來驅(qū)動(dòng)機(jī)械效率高表示什么,需要高性能的計(jì)算能力。第二種模型很簡(jiǎn)單,只是一條穿過原點(diǎn)的直線,也就是說,它的假設(shè)空間是全部
直線,訓(xùn)練的過程就是在所有這樣的直線中尋找最好的一條,哪一條是“最好的”? 我們稍后再說吧。 我們現(xiàn)在可以知道的是,簡(jiǎn)單的模型可以學(xué)習(xí)更少的問題,
這些模型只能將坐標(biāo)系分為兩部分,并學(xué)習(xí)二分類問題。 他們連三類問題都學(xué)不會(huì),甚至二類問題也學(xué)不會(huì)
它甚至無法學(xué)習(xí)這條直線,因?yàn)樗僭O(shè)空間中不存在這樣的直線。 另一方面,微軟的模型又高又復(fù)雜,可以學(xué)習(xí)k分類問題,盡管我可能需要大量數(shù)據(jù)和很多計(jì)算機(jī),但至少我有學(xué)習(xí)的可能性。
由上可知,機(jī)器學(xué)習(xí)模型假設(shè)空間的選擇需要在估計(jì)效率和待解決問題的復(fù)雜度之間進(jìn)行權(quán)衡。 解決簡(jiǎn)單的問題,我們需要一個(gè)簡(jiǎn)單的模型,這樣我們才能學(xué)習(xí)到性能好的模型,估計(jì)效率也高。 復(fù)雜問題上的復(fù)雜模型確保我們能夠?qū)W到一些東西,并且需要更多的數(shù)據(jù)和估計(jì)資源來進(jìn)行訓(xùn)練。
2. 在假設(shè)的空間中哪一個(gè)是最好的?
通過前面的介紹,我們現(xiàn)在知道機(jī)器學(xué)習(xí)問題需要已有的基本假設(shè),然后在假設(shè)空間上搜索來尋找最優(yōu)模型。 哪些是最好的?
我使用線性模型作為例子。
我的輸入可以轉(zhuǎn)換成一個(gè)大小為1*784的鏈表。 我們可以理解有784個(gè)特征。 我們對(duì)每個(gè)特征進(jìn)行評(píng)分,最終結(jié)果表明它被分類到某個(gè)類別的可能性有多大。
比如我們判斷數(shù)字是否為0,
同理,判斷鏈表是否為1,也可以扣分
這樣,我們就有10個(gè)這樣的模型,我們就有10*784=7840個(gè)參數(shù)。 我們的學(xué)習(xí)過程其實(shí)就是找到最優(yōu)的7840個(gè)參數(shù),對(duì)應(yīng)784維特征空間中的10個(gè)超平面(雖然相當(dāng)于在二維平面中找到10條直線,但是輸入數(shù)據(jù)的維度很高,表示為超平面的直線)。 現(xiàn)在在這個(gè)模型中,我只需要輸入一張圖片,它就會(huì)告訴我這張圖片是[0,1,2,3,4,…..]的可能性是[0.01,0.03,0.8,0.09… .],我們知道模型預(yù)測(cè) 3。
那么哪些是最好的呢? SVM的最優(yōu)定義是這樣的。 模型給出的結(jié)果是一個(gè)1*10的字段,表示圖像是手寫數(shù)字0到9的可能性。SVM要求正確標(biāo)簽的分?jǐn)?shù)至少比其他分?jǐn)?shù)大1。 ,距離這些狀態(tài)越近越好。
例如,預(yù)測(cè)結(jié)果為[0.01, 0.01, 0.9, 0.01….]的模型肯定優(yōu)于[0.1, 0.1, 0.6, 0.05,…..](SVM的預(yù)測(cè)分?jǐn)?shù)可以小于1,這里是為了說明“可能性”,舉的例子都大于1)。 定義的最優(yōu)值與SVM不同。 首先對(duì)線性模型的結(jié)果放一個(gè)函數(shù),將結(jié)果壓縮到[0,1]的范圍來表示概率,然后估計(jì)與真實(shí)結(jié)果的交叉熵交叉。 交叉熵越大,交叉熵?fù)p失函數(shù)越小越好。 這里引入的損失函數(shù)(loss/)實(shí)際上是“最好”的物理表達(dá)。例如SVM的損失函數(shù)為
損失函數(shù)意味著模型的當(dāng)前狀態(tài)偏離我定義的“最優(yōu)”越多,損失函數(shù)就越大,所以找到最優(yōu)模型就是最小化損失函數(shù)。
3. 如何搜索最優(yōu)模型
我們已經(jīng)知道機(jī)器學(xué)習(xí)就是在我們的假設(shè)空間中找到一個(gè)最優(yōu)模型,而最優(yōu)模型就是最小化損失函數(shù)。 如何最小化損失函數(shù)就對(duì)應(yīng)了我們要解決的“如何尋找最優(yōu)模型”。
我們知道機(jī)器學(xué)習(xí)是不斷調(diào)整參數(shù),直到損失最小化。 也就是說每一個(gè)變化都會(huì)引起變化。這里引入微積分來估計(jì)Loss的梯度
梯度表示在當(dāng)前狀態(tài)下,W每減少dW,b減少db,損失函數(shù)就會(huì)減少。 如果我每次讓W(xué)和b按照dW和db的范圍減小,損失函數(shù)就會(huì)減小一定量。因此學(xué)習(xí)/訓(xùn)練過程可以表示為
一般是一個(gè)很小的數(shù),以免學(xué)習(xí)范圍太大而達(dá)不到最優(yōu)點(diǎn)。
總結(jié)
機(jī)器學(xué)習(xí)的問題非常復(fù)雜,復(fù)雜性主要表現(xiàn)在:解決復(fù)雜問題所需的模型也復(fù)雜,復(fù)雜的模型帶來更多的參數(shù)、更多的數(shù)據(jù)需求、更大的計(jì)算能力。 在我們的設(shè)計(jì)假設(shè)有空間的時(shí)候會(huì)有很多的設(shè)置等等。 當(dāng)我們面對(duì)新的機(jī)器學(xué)習(xí)問題時(shí),我們需要思考的是:
1. 我使用多復(fù)雜的模型?
超平面可以在線性模型中工作嗎? 多個(gè)超平面可以在線性模型中工作嗎? 不是,那么做非線性模型,有隱藏層的神經(jīng)網(wǎng)絡(luò)能行嗎? 兩個(gè)呢? 十樓呢? ...(事實(shí)上,尋找特征往往比選擇模型更重要)
2. 我對(duì)最佳模型的定義是什么?
使用哪個(gè)損失函數(shù)? 什么樣的交叉熵? 什么樣的支持向量機(jī)?
3.如何找到最好的?
梯度增長(zhǎng)? 其他方法?
上述三個(gè)問題背后都有大量的理論支撐。 學(xué)完這個(gè)理論后,你會(huì)發(fā)現(xiàn)機(jī)器學(xué)習(xí)和深度學(xué)習(xí)是一系列物理、計(jì)算機(jī)和統(tǒng)計(jì)工具的結(jié)合。 您對(duì)工具的理解還需要您掌握領(lǐng)域知識(shí)以及對(duì)數(shù)據(jù)或業(yè)務(wù)需求的敏感性。
在量化投資領(lǐng)域機(jī)械效率高表示什么,機(jī)器學(xué)習(xí)更像是一套驗(yàn)證你投資想法的工具。 我們不可能把它當(dāng)作一個(gè)黑匣子,輸入一些訓(xùn)練數(shù)據(jù),得到一個(gè)通用的預(yù)測(cè)模型。 不知道這一點(diǎn)很容易誤入歧途。
前面我們會(huì)在機(jī)器學(xué)習(xí)這條主線的基礎(chǔ)上介紹一些例子,主要介紹工具的使用。 使用的環(huán)境主要是++。 上次更新啦!