DPA-1型號是在DP系列型號基礎上的全面升級,具有以下優點。
首先,該模型使用類似于自然語言處理領域中的注意力機制的門控注意力機制來完全建模原子之間的相互作用,這使得模型可以在現有數據條件下學習更多。 隱含的原子交互信息可以有效提高模型在不同數據集之間的遷移能力以及數據生成過程中的采樣效率。
其次,模型包含編碼元素分子勢能,不同元素使用相同的網絡參數,有利于擴展模型的元素容量。
同時,由于該模型是在56個元素的大數據集上進行預訓練,并完成多個下游任務的遷移學習,因此在保證預測精度的同時,可以大大降低訓練成本和訓練數據量。
此外,該模型具有超高的推理效率,可以進行大規模的分子動力學模擬。
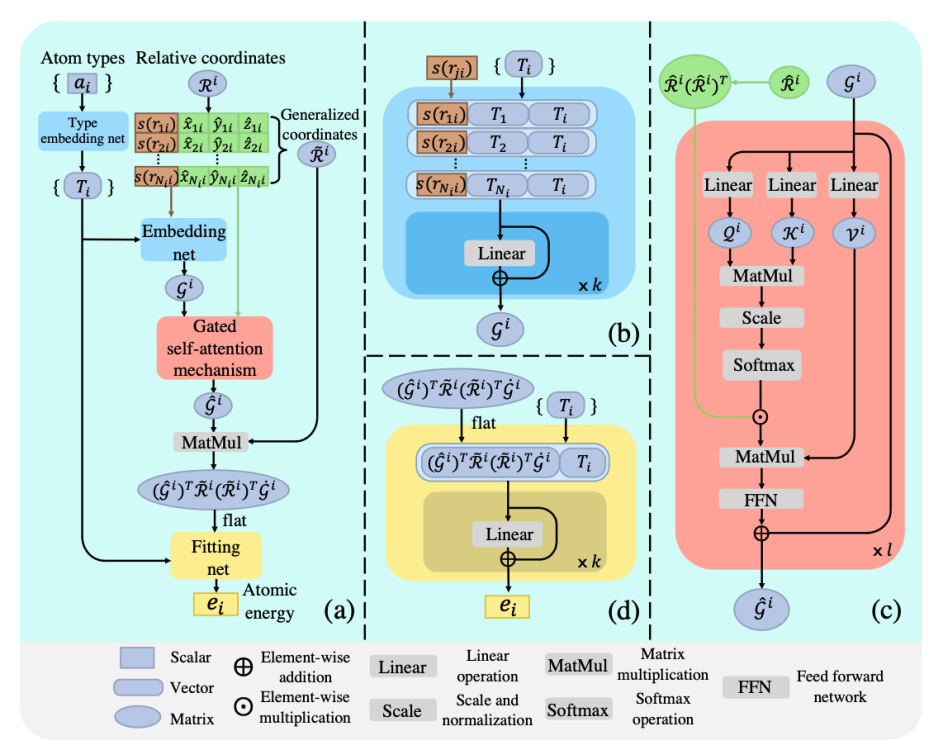
▲圖| DPA-1模型示意圖(來源:arXiv)
為了有效避免傳統模型的局限性,開發人員進行了多次有針對性的實驗。
開發人員首先將不同的訓練集劃分為多個子集,然后訓練一些子集,同時測試其他子集。 需要注意的是,這里每個子集的構象和組成都是不同的。 例如,數據集中,子集中只有單元素數據,子集中只有二進制數據,子集中只有三元數據。
最后,開發人員在三種類型的數據集上測試了 DPA-1 和 -SE 這兩個模型的性能:合金、固態電解質(SSE,固態)和高熵合金(HEA,High-)。 結果表明,與-SE相比,DPA-1的測試精度可提高一到兩個數量級,充分說明了后者強大的遷移能力。
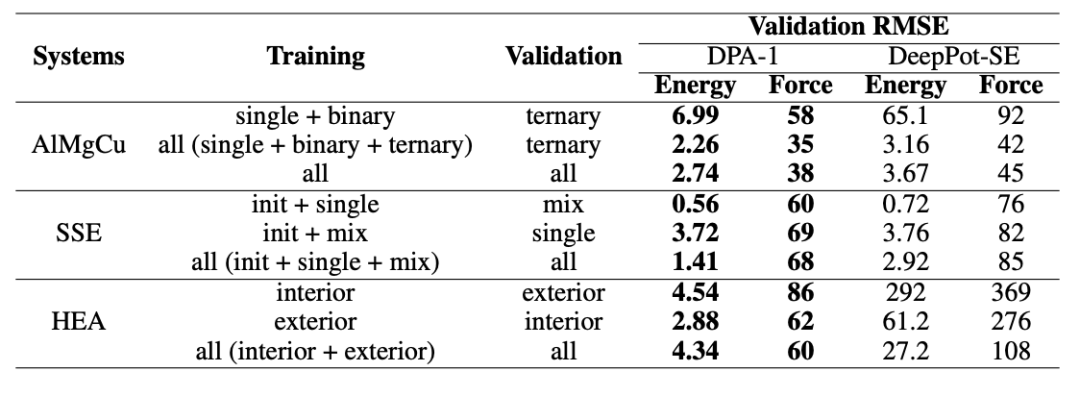
▲圖| 在不同訓練集上測試時獲得的結果(來源:arXiv)
在“預訓練+少量數據微調”的模型制作范式下,開發人員為DPA-1規劃了遷移學習解決方案。 首先對大規模數據進行模型預訓練,然后利用新數據集的統計結果修正最后一層的能量偏差,并將其作為訓練新任務的起點。
例如,對數據集中的一元和二元數據進行預訓練,對三元數據完成測試。 接下來,在OC2M數據集上進行預訓練工作,然后分別遷移到HEA和AlCu數據集。 結果表明分子勢能,DPA-1不僅可以在只有三元數據的場景下獲得更高的準確率,而且可以有效減少對下游訓練數據的依賴。
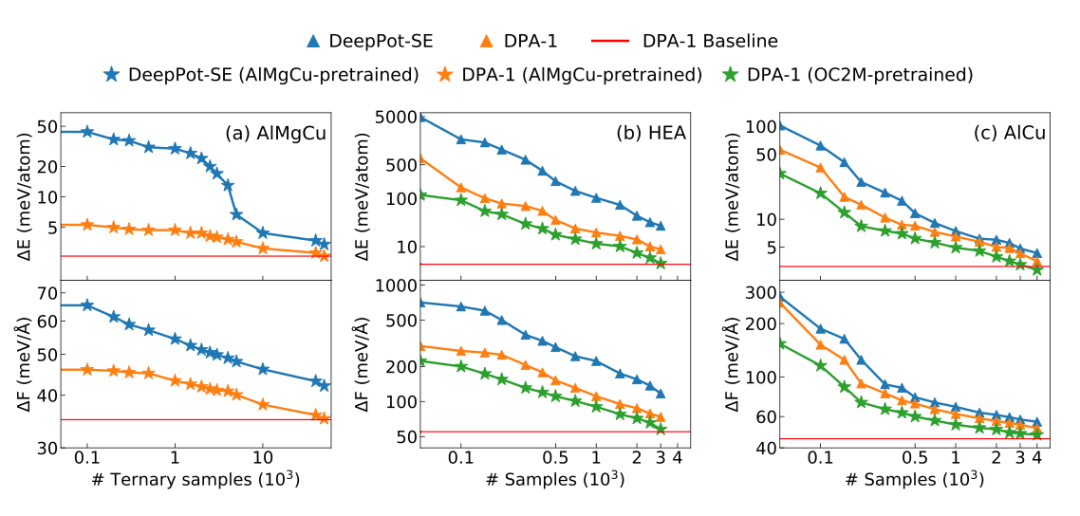
▲圖| DPA-1和-SE在不同數據集上的學習曲線(來源:arXiv)
開發人員還對 DPA-1 中編碼的元素參數進行了 PCA 降維和可視化。 結果表明,隱藏空間中的所有元素均呈螺旋狀分布,同一時期的元素沿螺旋下降趨勢分布,同一族元素垂直于螺旋分布。 這種分布模式因其在元素周期表中的位置而巧妙。 對應關系可以很好地證明模型的可解釋性。
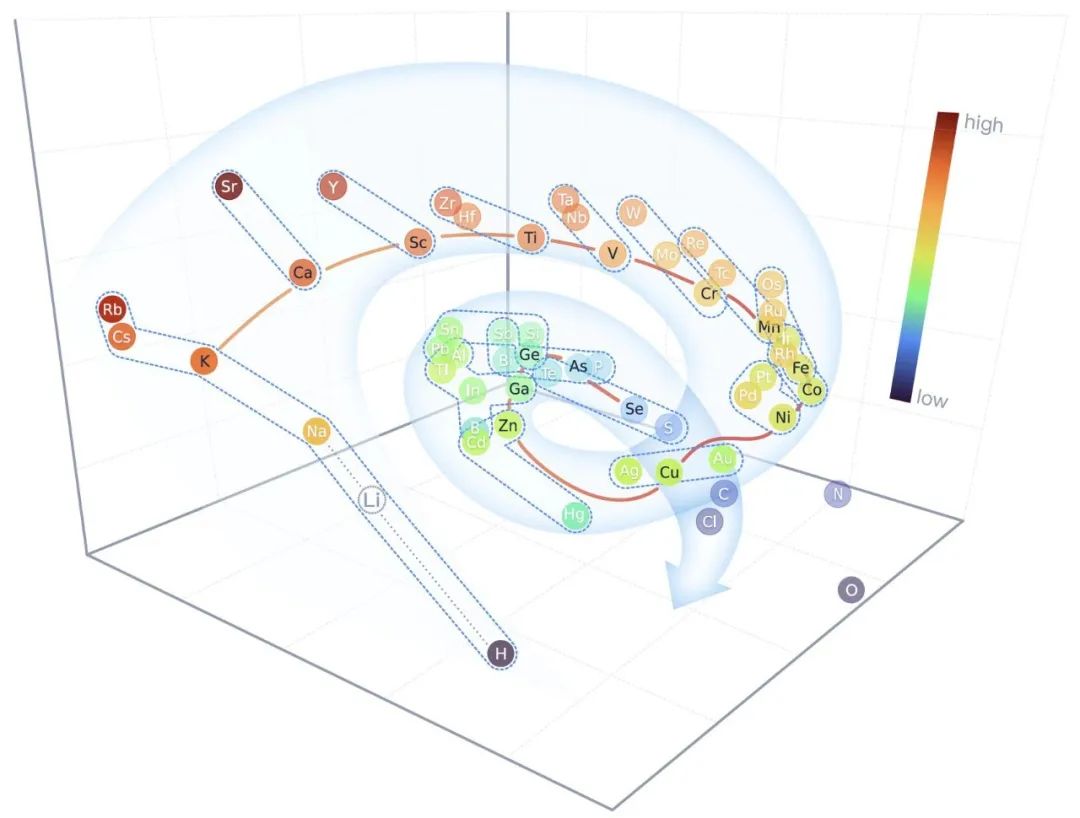
▲圖| PCA降維及可視化性能圖表(來源:arXiv)
目前,團隊已在其科學計算云平臺上完成了DPA-1的開源工作。 DPA-1的訓練和分子動力學模擬功能的開源也在開源社區的-kit項目下實現。
該團隊表示:“未來,我們將繼續致力于勢能函數的自動化生產和自動化測試,并繼續專注于多任務訓練、無監督學習、模型壓縮和蒸餾等操作。此外,更大更全的數據庫、下游任務和dflow工作流框架的結合也是發展的方向。”

參考:
1.Duo,Z.,Hang,B.等人。 DPA-1:基于 of 的深度模型。 arXiv (2022)。